
Big data zijn de gigantische collecties gegevens die bedrijven en overheden constant verzamelen. Aan het feit dat jouw persoonlijke gegevens op grote schaal verzameld worden, hangen nogal wat risico’s:
- Iemand steelt je data.
- Je hebt geen privacy meer.
- De data worden verkeerd geïnterpreteerd.
- De organisatie heeft foutieve data.
- Bedrijven verzamelen je gegevens met slechte intenties.
Gelukkig kun je jouw privacy ook met de opkomst van big data beschermen. Hiervoor hebben we enkele tips:
- Gebruik online niet je echte persoonsgegevens.
- Onthoud dat alles wat je op het internet zet, op het internet blijft.
- Gebruik adblockers.
- Gebruik anti-tracker en anti-cookie plug-ins.
- Log uit op websites die je niet gebruikt.
- Beveilig je internetverbinding middels Tor of een goede VPN, zoals NordVPN.
Benieuwd naar de manieren waarop we omgaan met big data? Of wil je weten hoe je jouw privacy het beste beschermt? Lees dan het hele artikel hieronder.
Er is de afgelopen decennia ontzettend veel veranderd in de wereld, met name op het gebied van ICT. Zo is het aantal mensen waar we mee kunnen communiceren enorm gegroeid, net als de hoeveelheid informatie die we kunnen raadplegen. Dit geldt echter ook voor de informatie die grote partijen over ons als internetgebruikers verzamelen.
Woorden als ‘big data’ horen we steeds vaker. Wat betekent dat nu eigenlijk? Wat is big data? Is het gevaarlijk? En wat voor effect heeft het op onze privacy? Dat zijn de vragen die we in dit artikel bespreken.
Wat is big data?
Met big data bedoelen we de gigantische collecties gegevens die constant verzameld worden. Denk aan alle informatie die Google bezit over de zoekopdrachten van zijn gebruikers. Deze verzamelingen zijn zo groot en complex dat ze lastig op de traditionele manier te analyseren zijn.
Big data bestaat, omdat bedrijven en andere partijen, zoals de overheid, steeds meer informatie over ons verzamelen. Nieuwe technologieën, digitalisering en met name het internet maken dit mogelijk. Als je big data-gegevens op de juiste manier analyseert, kun je bepaalde patronen en statistieken ontdekken. Zo wordt big data gebruikt om voorspellend marktonderzoek te doen. Welke producten zullen klanten sneller kopen? Wat voor advertenties zijn het effectiefst?.
Eigenschappen van big data
Big data is vaak te definiëren aan de hand van de volgende eigenschappen, ook wel de drie v’s genoemd:
- Volume (hoeveelheid). Big data is geen steekproef. Het is een kwestie van (ogenschijnlijk eindeloze) observatie en registratie.
- Velocity (snelheid). Dit gaat over de snelheid waarmee de informatie wordt verzameld. Big data is vaak direct en in real-time beschikbaar.
- Variety (variatie). Big data komt voort uit verschillende soorten gegevens en lost vaak missende informatie op door datasets te combineren.
Naast de drie v’s heeft big data nog een aantal kenmerken. Zo is het perfect voor machinaal leren. Dit betekent dat computers en andere vormen van kunstmatige intelligentie van de data kunnen leren. Vanwege de grote datasets kan men, met behulp van computers, op een uiterst effectieve manier patronen in big data detecteren. Ook komt big data vaak voort uit een digitale vingerafdruk. Dit betekent dat het een bijproduct van digitale activiteit is en kan helpen bij het opbouwen van een persoonsprofiel van gebruikers.
Welke soorten big data zijn er?
Je kunt big data op verschillende manieren indelen en categoriseren. De eerste en meest gebruikte manier verdeelt big data afhankelijk van het soort informatie dat het omvat. De drie mogelijke categorieën zijn vervolgens: gestructureerde, ongestructureerde en semigestructureerde big data.
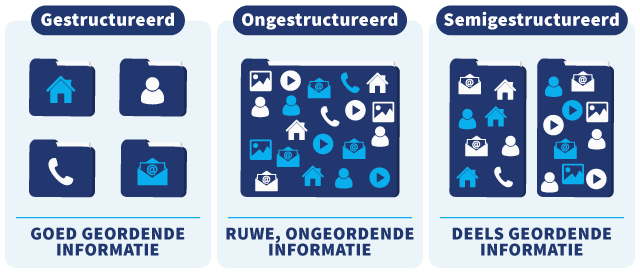
Gestructureerde big data
Wanneer big data gestructureerd is, is de informatie op een georganiseerde en geordende manier opgeslagen. Hierdoor is het toegankelijker en gemakkelijker om in te zien. Een voorbeeld van gestructureerde big data is een adressenlijst die in de database van een bedrijf staat. Hier staan namen, telefoonnummers en woonplaatsen van alle werknemers op een gestructureerde manier opgesomd, bijvoorbeeld in een nette tabel.
Ongestructureerde big data
Ongestructureerde big data is niet logisch of georganiseerd. Er ontbreekt een vorm of geordende weergave die betekenis aan de gegevens geeft. Omdat dit soort data geen logica heeft, is het een stuk moeilijker te navigeren en begrijpen dan gestructureerde data. Over het algemeen is een groot deel van verzamelde big data in eerste instantie ongestructureerd.
Een specifiek voorbeeld van ongestructureerde data is de ruwe data die websites over je verzamelen. Het samenraapsel van IP-adres, browser, betaalgegevens, apparaat en allerlei andere gegevens moeten samengevoegd worden om een profiel van je aan te maken. Dit profiel is dan dus (semi)gestructureerd.
Semigestructureerde big data
Semigestructureerde data is gestructureerde data die deels ongestructureerd is. Het is dus een combinatie van de twee eerdergenoemde vormen. Het is niet volledig willekeurig, maar ook niet netjes gerangschikt in een database voor goede analyse.
Als voorbeeld kijken we naar een webpagina die speciale metadata-tags bevat. Deze extra informatie die niet direct zichtbaar is geeft bijvoorbeeld aan dat er bepaalde trefwoorden voorkomen op de pagina. Deze tags geven informatie op een effectieve manier door, zoals de auteur van een tekst of het moment waarop deze online is gezet. De tekst zelf is in principe ongestructureerd, terwijl de trefwoorden en andere metadata het toch enigszins gemakkelijk te analyseren maken.
Indeling op basis van big data-bron
Een tweede indeling die mensen soms maken, is op basis van wie de big data heeft geleverd. In andere woorden, hoe is de data verzameld? Ook hier zijn er weer drie categorieën.
- Door mensen. Denk hierbij aan boeken, foto’s, video’s en informatie op websites en sociale media zoals Facebook, Twitter, LinkedIn, Instagram.
- Dankzij de registratie van processen. Dit zijn de meer traditionele vormen van big data die in de bedrijfswereld worden vergaard om bijvoorbeeld werkprocessen te optimaliseren. Een voorbeeld hiervan is het uren schrijven dat werknemers bij sommige bedrijven moeten doen.
- Door machines. Dit type big data komt voort uit de groeiende hoeveelheid sensoren in machines. De output van deze data is door machines gegenereerd en kan zowel erg simpel als ontzettend complex zijn. Denk aan temperatuurmetingen of hersengolfmetingen. Deze gegevens zijn vaak goed gestructureerd en vormen een compleet plaatje.
Wat kun je met big data doen?
Al deze informatie blijft nog heel breed. Laten we het eens wat concreter maken en de diepte in duiken. Er zijn heel veel verschillende manieren waarop bedrijven en organisaties big data gebruiken. Wellicht denk je allereerst aan de massa’s informatie die grote internetbedrijven, zoals Google, Facebook, Spotify en Amazon over ons verzamelen.
Facebook houdt data bij over al zijn gebruikers en bepaalt daarmee wat jij op je tijdlijn te zien krijgt, in de hoop dat dat aansluit op jouw interesses en je dus langer op de website blijft. Amazon verzamelt informatie over de pagina’s die klanten bezoeken en de producten die ze kopen. Daarmee kan Amazon suggesties geven, in de hoop zo meer geld te verdienen.
Big data in het dagelijks leven
Het gebruik van big data is wijdverbreid. Zo verzamelt de NS informatie over de drukte op verschillende trajecten en in treinen. Met deze data besluit het vervolgens waar extra treinen in te zetten en hoe de nieuwe dienstregeling eruit komt te zien.
Een ander bekend voorbeeld komt van UPS. De wereldwijde koeriersdienst gebruikt al een tijdje speciale software die uit big data voortkomt. Daarmee worden bochten naar links op hun route vermeden, omdat die gevaarlijker en duurder zijn. Met dit systeem bespaart UPS jaarlijks een gigantische hoeveelheid benzine.
De laatste tijd zien we dat gemeentes big data gebruiken om steden slimmer te laten functioneren. Big data speelt hiermee een belangrijke rol in smart cities. Steden kunnen gegevens van IoT (Internet of Things)-apparaten en sensoren verwerken om patronen en behoeften te herkennen.
Niet alle big data is online
Een ander voorbeeld van big data valt binnen een interessante categorie, omdat dit zowel on- als offline kan plaatsvinden. Het betreft DNA testen en familiestamboom-websites. Denk bijvoorbeeld aan een website als myheritage.nl. Dit is een website waarmee je tot vele generaties terug je familiestamboom en etniciteit kunt bepalen. Mensen die hier gebruik van maken geven veel persoonlijke informatie over zichzelf prijs en dit is dan ook een andere manier waarop bedrijven big data verzamelen en gebruiken.
Ook ’traditionele’ fysieke DNA-testen hebben uiteraard extreem veel data nodig. Je kunt dan ook stellen dat afnemers van deze testen een van de grootste big data-verzamelaars zijn. Tegelijk kun je je voorstellen, als het om zoveel persoonlijke gegevens gaat, dat hier risico’s aan kleven. Over de mogelijke risico’s lees je meer in het volgende deel van de tekst.
Is big data gevaarlijk?
Big data is in veel gevallen ontzettend handig. Het zit boordevol informatie. Deze informatie kunnen we vervolgens gebruiken om processen te verbeteren, onze aanpak te veranderen of zelfs een heel bedrijf beter te laten functioneren. Dit betekent echter niet dat het vergaren en gebruiken van big data geen nadelen heeft. Hieronder bespreken we de vijf belangrijkste risico’s die big data met zich meebrengen:
- Data wordt gestolen of gehackt.
- Het beperkt je privacy.
- De data-interpretatie verloopt slecht.
- De data zelf is slecht.
- Big data wordt met de verkeerde intenties verzameld.
Hackers en dieven
Bij alles wat we online doen, moeten we stilstaan bij de mogelijkheid dat iemand databases kan hacken en onze informatie en gegevens over ons internetgedrag steelt. Het aantal datalekken en digitale inbraken is over de jaren fors toegenomen. Je leest regelmatig berichten over nieuwe datasets met wachtwoorden die criminelen online verkopen, bijvoorbeeld op het dark web. Deze wachtwoorden komen meestal uit de databases van officiële instanties, websites en bedrijven.
Hoe ‘bigger’ de data, hoe interessanter het voor potentiële dieven is om te stelen. Oftewel, hoe meer informatie er over jou in een dataset is opgenomen, hoe meer dit waard is om door te verkopen. Dit maakt natuurlijk inbreuk op je privacy, maar hackers kunnen hierdoor ook grote problemen veroorzaken. Zo kan iemand je identiteit stelen en zo je bankrekening leegplunderen.
Privacy
Steeds meer partijen verzamelen informatie over je. Hoewel de technologie continu verder vooruit streeft, zijn er echter niet altijd duidelijke regels over hoe de privacy van gebruikers beschermd moet worden. Er zijn uiteraard wel wetten en instanties, zoals de Algemene verordening gegevensbescherming (AVG) en de Autoriteit Persoonsgegevens (AP), maar daartegenover staan weer wetten zoals de zogenaamde Sleepwet. Bovendien vertonen veel bedrijven in de praktijk niet voldoende transparantie om een geïnformeerde beslissing over je privacy te maken.
Het blijft dus onduidelijk welke gegevens een bedrijf mag verzamelen en wie er precies toegang krijgt tot deze informatie. Zeker gezien het feit dat grote databestanden waarschijnlijk privacygevoelige informatie bevatten, is dit toch een cruciaal punt om bij stil te staan. Deze privacygevoelige gegevens kunnen immers door iedereen misbruikt worden, niet alleen door hackers. Wat doen die grote bedrijven, zoals je eigen internetprovider, bijvoorbeeld met jouw info?
Meer over de privacyrisico’s en hoe je deze verkleint, vertellen we je later in dit artikel meer.
Slechte data-analyse
De reden dat verschillende bedrijven en organisaties big data verzamelen, is omdat ze er interessante analyses op los kunnen laten. Hierdoor krijgen ze mogelijk nieuwe inzichten die ze in de toekomst slim kunnen gebruiken. Net als bij het analyseren en onderzoeken van normale datasets, brengt een verkeerde interpretatie en analyse van grote datasets echter grote potentiële risico’s met zich mee. Dit kan namelijk tot verkeerde conclusies leiden.
Een wetenschappelijk artikel in PNAS uit 2017 toont enkele voorbeelden van zulke slechte data-analyse. Een voorbeeld dat de onderzoekers aanhalen is een onderzoek naar de relatie tussen hartritmestoornissen en diabetes type 2. Hoewel onderzoek een correlatie aantoonde, dus een nog ongedefinieerd verband, bracht de media de resultaten naar voren als het volgende: “Het probleem van ons landelijk dieet: bijna duizend doden door hart- en vaatziekte en diabetes door slechte eetgewoonten”.
Het probleem met big data specifiek is dat het goed werkt om correlaties aan te tonen, maar moeite heeft met causatie. Je kunt dus vaak niet afleiden welke variabele effect heeft op de andere, alleen dat er een verband bestaat. Denk maar aan de relatie die gevonden werd tussen de groei van Internet Explorer en de hoeveelheid moorden in de VS tussen 2006 en 2011. Stellen dat het een de oorzaak is van het ander is echter niet mogelijk.
Slechte data
Big data is erg populair en steeds meer bedrijven en organisaties verzamelen dus veel informatie. Zij verzamelen deze data echter vaak eerst en denken daarna pas na over een eventuele analyse. Je loopt vervolgens het risico dat je verkeerde of irrelevante data verzamelt en analyseert. Dit leidt weer tot het uitblijven van resultaten of het trekken van verkeerde conclusies.
Dit kan op een simpele manier misgaan, door bijvoorbeeld verkeerde namen aan e-mailadressen te koppelen. Jij krijgt dan bijvoorbeeld een e-mail die eigenlijk naar je net overleden tante gestuurd had moeten worden. Dat is erg pijnlijk natuurlijk. Het kan echter op een ergere manier misgaan. Denk aan het baseren van keuzes rondom kindertoeslag op basis van nationaliteit. De belastingdienst had hier een incomplete lijst van mensen met een dubbele nationaliteit en nam dit mee in de controle op fraude.
Registratie big data met verkeerde intenties
Het verzamelen van big data wordt ook steeds meer door bedrijven, instanties en overheden gedaan om profielen van personen te maken. Hierbij krijgen gebruikers of burgers in vrijwel alle gevallen te weinig informatie over welke persoonsgegevens geregistreerd worden en hoe de organisaties dat doen. Dit heeft grote negatieve gevolgen voor hun privacy. Alles wat ze (online) doen, kan opgeslagen worden.
Bovendien kunnen big data-verzamelaars met wat onderzoek en analyse van de verzamelde data gemakkelijk de beslissingen van mensen beïnvloeden en manipuleren. Het Facebook-algoritme bepaalt bijvoorbeeld welke artikelen je wel en niet leest, waardoor je makkelijk in een informatiebubbel terecht komt. Ook gebruikt deze dienst de zogenaamde ‘Facebook pixel’, een soort spyware, waardoor het bedrijf te weten komt welke reclames het aan jou moet tonen.
Daarnaast zijn er genoeg bedrijven die je persoonlijke informatie doorverkopen. Misschien was het bij het opzetten van het bedrijf niet de intentie, maar zoals het gezegde gaat: als een product of dienst gratis is, ben jij het product. Denk maar aan Grindr die persoonsgegevens doorverkocht aan advertentiemaatschappijen.
Big data en privacy
Er zitten dus flink wat nadelen en risico’s aan big data. Aangezien het voor bedrijven ook veel voordelen met zich meebrengt, wordt het wel veel gedaan. Vaak gebeurt dat zelfs in het geheim. Dit heeft grote gevolgen voor onze privacy.
We hebben het al even kort gehad over de mogelijke gevaren voor privacy wanneer partijen big data registreren met verkeerde intenties. Omdat privacy zoveel raakvlakken met het verzamelen van gegevens heeft, willen we hier echter nog even dieper op ingaan.
Massa dataverzameling
Veel bedrijven, zoals Google, Facebook en Twitter, zijn door hun verdienmodel voor een groot deel afhankelijk van advertenties. Om deze zo effectief mogelijk te maken, creëren ze persoonsprofielen van hun gebruikers. Ook voor overheden en geheime diensten is big data erg belangrijk geworden. Zij gebruiken informatie over individuen om burgers te volgen en te controleren.
Als er zoveel data over ons wordt verzameld, zijn er natuurlijk ook veel data voor kwaadwillende partijen om te manipuleren. Dit is gevaarlijk. Doordat we te maken hebben met steeds meer digitalisering, wordt het verzamelen van gegevens bovendien steeds gemakkelijker.
Datacollectie gebeurt vaak op manieren waarbij de bezoeker of burger dit zelf niet door heeft. Wie leest immers de privacyverklaring en terms of service van elke dienst die hij gebruikt? Hierdoor zijn we niet echt op de hoogte van de gegevens die bedrijven en instellingen over ons hebben, terwijl de hoeveelheid data toe blijft nemen.
Door het samenvoegen van datasets en verdere analyse komen er vaak nóg meer privacygevoelige gegevens en informatie naar boven. Zo weten bedrijven al snel meer over je dan je mogelijk over jezelf weet. Wie je bent, waar je woont, wat je hobby’s zijn, wie je vrienden zijn: al deze informatie is niet langer privé. Geen fijn idee, zul je vast denken. Gelukkig staan we er niet helemáál alleen voor.
Privacywetgeving: de Algemene verordening gegevensbescherming
De impact van big datasets op je privacy is erg groot, zoals je hierboven hebt kunnen lezen. Door middel van wetgeving worden we gelukkig deels tegen deze privacyinbreuk beschermd. De AVG die in 2018 in de Europese Unie is ingevoerd, is hier een belangrijk onderdeel van. Deze nieuwe privacywet geeft burgers meer rechten en beschermt deze rechten beter.
Hierdoor kun je nu bijvoorbeeld een verzoek indienen bij Google en andere organisaties om je persoonlijke gegevens uit de zoekresultaten of van de websites te laten verwijderen. Hoe je dit doet, leggen we voor een groep sociale media uit in de ‘wat weet’-artikelen. Ook worden bedrijven zoals Facebook (in theorie) flink voor het blok gezet met betrekking tot de informatie die het over zijn gebruikers verzamelt, waardoor het flinke boetes riskeert, als het zich niet aan de AVG houdt.
De huidige (privacy)wetgeving werkt helaas niet perfect. Vooral als het gaat om big data schiet deze vaak tekort, waardoor er zelfs legaal privacy schendende activiteiten plaatsvinden. Naast deze legale activiteiten, hebben klokkenluiders als Edward Snowden en Chelsea Manning grote illegale gevallen van big data-registratie aan het licht gebracht.
Er is dus ook in de media steeds meer aandacht voor de privacyrisico’s van big data. Dit is de eerste stap in een lang proces naar een verbeterde privacywetgeving die past bij deze tijd. Als het om je privacy gaat, wil je echter niet jaren wachten tot de wet je eindelijk goed beschermd. Veel mensen zullen zich dan ook afvragen wat ze zelf kunnen doen tegen de privacyrisico’s van big data. Gelukkig zijn er wel een aantal trucjes die je daarbij kunnen helpen.
Hoe word je niet opgenomen in online big data-sets?
Big data-sets kunnen in veel gevallen problematisch zijn voor je privacy en veiligheid. Deze massale verzamelingen aan informatie bevatten namelijk persoonlijke data over jou en je (internet)gedrag. Deze grote hoeveelheid gegevens kan op allerlei manieren tegen je worden gebruikt, of dit nu gedaan wordt door marketingbedrijven of cybercriminelen. Je doet er dus goed aan te zorgen dat er zo min mogelijk data over je wordt opgeslagen.
Hieronder vind je stappen die een goed begin zijn om jouw privégegevens te beschermen. Big data wordt echter op veel meer plekken dan alleen het internet verzameld, dus houd daar altijd rekening mee. Wil je weten welke informatie een bepaald bedrijf over jou heeft vergaard? Dan heb je onder de AVG bovendien altijd het recht om hier vraag naar te doen.
- Gebruik online je echte gegevens zo min mogelijk. Vul bijvoorbeeld waar mogelijk niet je echte naam, adres, telefoonnummer en e-mailadres in. Ook internetwachtwoorden kun je het best zo onpersoonlijk mogelijk maken.
- Houd de volgende gedachte in je achterhoofd: alles wat je op het internet zet, blijft er voor altijd op staan. Dit is misschien niet in alle gevallen volledig waar, maar het helpt wel. Als je constant rekening houdt met deze mogelijkheid, beperk je de hoeveelheid privégegevens die je deelt automatisch. Lees ons stappenplan over hoe je jezelf van het internet verwijdert voor meer informatie over het (geleidelijk) wissen van je gegevens.
- Gebruik één (of meerdere) advertentie-blokkerende browser plug-ins.
- Gebruik één (of meerdere) browser plug-ins die trackers en cookies blokkeren.
- Wis regelmatig je tijdelijke internetbestanden en cookies.
- Log uit op sites als je ze even niet gebruikt.
- Zorg ervoor dat je internetverbinding beveiligd en geanonimiseerd is, bijvoorbeeld door gebruik te maken van de Tor-browser en/of een VPN.
Veilig en anoniem internetten met een VPN
Advertentieblokkers en andere plug-ins zijn bij de meeste mensen al wel bekend. Een Virtueel Particulier Netwerk (VPN) is daarbovenop een erg goede aanvulling om je privacy online te waarborgen. Een VPN versleutelt je data, waardoor het veilig het internet opgaat en niet door hackers te onderscheppen is. Daarnaast leidt de VPN al je informatie om via een externe server. Websites en organisaties weten zo niet vanuit welke locatie jij het internet opgaat. Je hebt immers je IP-adres gewijzigd op deze manier.
Uiteraard kun je jouw eigen onderzoek doen naar de VPN die het meest voor jou geschikt is. Wij kunnen je echter zeker NordVPN aanbevelen. Dit is momenteel de beste VPN op alle fronten. Het biedt zeer goede informatiebeveiliging en door zijn vele servers over de hele wereld, kun je geheel anoniem het internet op.
De vele wereldwijde servers bieden daarnaast unblocking-mogelijkheden. Zo heb je geen last meer van geoblokkades wanneer je naar de Amerikaanse Netflix of internationale sportwedstrijden wilt kijken.
Conclusie
Steeds meer partijen maken gebruik van big data om op basis van privégegevens bijvoorbeeld trends te voorspellen. Hierdoor loop je een steeds groter risico dat je persoonsgegevens op straat komen te liggen, door hackers bijvoorbeeld. Ook kunnen bedrijven al deze persoonlijke informatie doorverkopen aan advertentiebedrijven.
Gelukkig kun je zelf stappen zetten om je online privacy beter te waarborgen. Een van deze stappen is het installeren van een goede VPN, zoals NordVPN. Al zijn er natuurlijk ook andere hele goede opties.
Heb je een vraag waar je kort antwoord op wilt? Lees dan onze FAQ of stel je vraag in de reacties.
Big data is te definiëren aan de hand van hoeveelheid, snelheid en variatie. Het is dus een database van heel veel verschillende observaties die heel snel verzameld worden. Dit is ideaal voor machinaal leren. Deze machines kunnen structuur aanbrengen in de big data en zo bijvoorbeeld een persoonsprofiel van gebruikers opstellen.
Dit leidt natuurlijk tot de nodige privacyrisico’s. Denk maar aan hackers die toegang krijgen tot al jouw persoonlijke gegevens.
Big data is de collectie van alle grote databases aan informatie die een organisatie verzamelt.
AI staat voor artificial intelligence, oftewel kunstmatige intelligentie.
Deze twee zijn dus niet hetzelfde. Big data kan echter wel gebruikt worden om AI te voeden, waardoor het bijvoorbeeld leert patronen te herkennen.
Bedrijven en overheden gebruiken big data om trends te analyseren. Zo krijgen ze informatie over welke advertentiecampagnes het beste zouden werken of welk beleid gevoerd moet worden.
Dit is echter niet altijd even makkelijk. Er zitten namelijk een aantal nadelen aan deze gigantische hoeveelheid ongestructureerde data.
Big data is meestal ongestructureerd. Hierdoor heeft het enkele nadelen:
- De data kunnen verkeerd geïnterpreteerd worden.
- Er zitten foutieve data in de database.
Bovendien kunnen bedrijven en criminelen de verkeerde intenties hebben met jouw gegevens. Lees hierover meer in ‘Big data en privacy‘. Hierin vertellen we je ook hoe jij je privacy kunt waarborgen.
Je kunt je privacy tot op zekere hoogte beschermen tegen de dataverzameling van grote bedrijven. Enkele manieren waarop je dat doet, zijn:
- Het installeren van adblockers en anti-trackers.
- Niet je eigen informatie prijsgeven op het internet.
- Een VPN downloaden.
Andere maatregelen die je kunt treffen, lees je in ‘Big data en privacy‘.



